
AI Due Diligence (2026): 5-Layer Audit + EU AI Act Map + 12 Deals

Co-founder and CEO at Peony. I built the data room platform with a background in document security, file systems, and AI. Founded Peony in 2021 in San Francisco.
Last updated: May 2026
Quick answer: AI due diligence has two halves in 2026. The first is DD-of-AI — auditing an AI-using target through the 5-Layer AI Target Audit (Data / Model / Infrastructure / Output / Governance) scored 5 to 25, with bands at 5-10 walk, 11-17 price-chip, 18-25 healthy. The second is AI-for-DD — using AI tools to speed clause extraction, redline summarization, and Q&A routing inside the data room with source-citation enforced. The EU AI Act high-risk obligations enter application on 2 August 2026 unless deferred by the November 2025 Digital Omnibus to 2 December 2027; until that proposal is formally adopted, deal counsel still prices to the August 2026 baseline. Anchor precedents: SpaceX-xAI $1.25T (Feb 2026), Bartz $1.5B settlement (Sep 2025), NYT 20-million-log discovery order (Jan 2026), HSR threshold $133.9M (Feb 17 2026).
I run Peony, a virtual data room platform. The frames in this post come from a year of fielding questions from corp-dev associates evaluating AI-using targets, PE deal partners running platform diligence on AI-assisted services, in-house GCs scoping AI policy disclosures for buy-side, EU AI Act compliance counsel mapping target tier exposure, and AI-product founders preparing sell-side diligence packets. The question that defines this work in 2026: what specifically does an AI target's data room need to surface that a generic tech target does not, and how do you score it?
This post is the AI Due Diligence anchor — the dual-frame deep dive covering both how to audit a target that uses AI (the 5-Layer AI Target Audit) and how to use AI to run faster DD across any target. It anchors against twelve recent deal anchors and integrates the EU AI Act August 2026 enforcement calendar into the data room scope and gating model.
TL;DR — the 5-Layer AI Target Audit plus EU AI Act Exposure Scoring Matrix defines the playbook:
- The 5-Layer AI Target Audit: Data Layer (training provenance, PII, scrape risk) + Model Layer (proprietary vs licensed, license-cliff terms) + Infrastructure Layer (GPU contracts, cloud concentration, BIS export-control posture) + Output Layer (FTC AI-claims exposure, indemnification posture) + Governance Layer (EU AI Act tier, NIST AI RMF, red-teaming cadence). Each layer scored 1-5. Composite AI Deal Health Score from 5 to 25. Bands: 5-10 walk, 11-17 price-chip, 18-25 healthy.
- The EU AI Act Exposure Scoring Matrix: four tiers (Unacceptable / High-Risk / Limited / Minimal) mapped onto the target's use cases. The 2 August 2026 high-risk enforcement date is the deal-cycle relevant timestamp; the November 2025 Digital Omnibus would defer to 2 December 2027 if formally adopted.
- The AI-for-DD playbook (short): clause extraction, contract redline summarization, Q&A routing, financial-statement reconciliation. Real lift, real audit trail. Avoid black-box "risk scores" with no source citation.
- The Peony spine: NDA gates before AI-specific subfolders are visible, visitor groups so the AI specialist counsel tier sees the model-card archive without the operations tier accessing it, page-level analytics tracking which AI-target documents reviewers spent time on (the engagement signal tells the seller where the price-chip ask will land), dynamic watermarks on every model-card and training-data manifest, and auto-indexing recognizing the typical AI-target document inventory (model cards, eval suites, red-team reports, AI risk registers).
What does "AI due diligence" actually mean in 2026?
AI due diligence in 2026 is a dual-frame discipline combining DD-of-AI (auditing an AI-using target through the 5-Layer AI Target Audit) and AI-for-DD (using LLM tooling with source-citation enforced to speed any DD workflow). The first frame is DD-of-AI — auditing a target company that builds, uses, or sells AI, with structured attention to the AI-specific risk surface that a generic tech audit does not catch. The second frame is AI-for-DD — using AI tools (LLMs, RAG systems, clause-extraction engines) to accelerate the workflow of running any due diligence, AI target or not. Most practitioners use the phrase loosely to mean one or the other. Sophisticated buyers and counsel use both.
The DD-of-AI frame is the heavier of the two and the focus of this post. It exists because the AI risk surface is structurally different from the standard tech-target risk surface: training data is not source code, model licenses do not behave like software licenses, GPU capacity is not commodity cloud, hallucination is not a software bug, and the EU AI Act is not GDPR. A generic "tech DD" — code-quality review, open-source license scan, GDPR exposure, SOC 2 trail, infrastructure security — misses five categories of liability that show up only when you scope specifically for AI: pirated training corpora, third-party model terms with user-count cliffs, GPU contract concentration risk, FTC AI-claims exposure, and EU AI Act tier obligations. The 5-Layer AI Target Audit is the diligence frame that names and scores each of those five layers. The hub-canonical playbook for the broader workstream sits in M&A solutions and due diligence solutions; private-equity buyers running platform-level AI-DD on add-ons should also map this against the private equity solutions page.
The AI-for-DD frame is increasingly material because the AI-tooling for diligence has crossed a usefulness threshold around 2024-2025. Clause extraction across hundreds of customer contracts (caps, indemnities, change-of-control, MFN, exclusivity) is now a 4-to-6-hour run rather than a 4-to-6-day grind. Q&A routing on inbound buyer questions can be automated against a tagged document store. Redline summarization on amendment stacks is reliable when the source-citation requirement is enforced. The honest test, applied throughout this post: can the AI tool cite the source paragraph for every finding, and would the buyer's counsel sign off on the methodology in a deposition?
The phrase "AI due diligence" in market usage typically means one of three things: (1) the dedicated DD-of-AI workstream when the target builds or uses AI as a material part of revenue, (2) the AI-for-DD application of language models to speed any DD workflow, or (3) the regulatory and policy disclosure scope under the EU AI Act and emerging US frameworks. This post covers all three in sequence. The DD-of-AI workstream is the structural core because it is the workstream where buyer counsel signs off on actual repricing, indemnification, and walk-away decisions.
The 5-Layer AI Target Audit applies to any target where AI is material to revenue, product, operations, or risk profile. That includes the obvious cases (AI labs, AI products, AI infrastructure) and the less obvious ones (any SaaS company that has added an AI feature in the last 18 months, any consumer product with an AI assistant, any regulated business — credit, recruitment, healthcare, biometric ID — that has deployed AI in a covered use case). For targets where AI is not material, the audit reduces to a single-page screening checklist; for targets where AI is the product, it becomes the gating workstream of the entire deal.
How does the EU AI Act change M&A pricing for AI targets?
The EU AI Act changes M&A pricing for AI targets through four mechanisms — tier-driven compliance cost, deferred enforcement uncertainty, GPAI-model obligations that already entered force in August 2025, and the conformity-assessment evidence requirement for High-Risk systems. The deal-cycle relevant date is 2 August 2026, when the obligations regarding high-risk systems listed in Annex III, the Article 50 transparency requirements, and the measures in support of innovation enter application. Until and unless the European Commission's Digital Omnibus on AI (published 19 November 2025) is formally adopted to defer high-risk obligations to 2 December 2027, deal counsel must price against the August 2026 baseline.
| Tier | Enforcement date | Example use cases | Deal-cycle action |
|---|---|---|---|
| Unacceptable | Applied 2 Feb 2025 | Social scoring, real-time biometric ID in public spaces, manipulative techniques | Walk for any EU-touching buyer |
| High-Risk (Annex III) | 2 Aug 2026 (or 2 Dec 2027 if Omnibus adopted) | Recruitment scoring, credit scoring, biometric ID, critical infrastructure | Price-chip $200K-$2M readiness chip; conformity assessment file required |
| Limited-Risk | 2 Aug 2026 | Chatbots, synthetic-content generators | Article 50 transparency disclosure required |
| Minimal-Risk | No obligation | Internal ops AI, productivity assistants | No AI-specific repricing |
Mechanism one — tier-driven compliance cost. The Act establishes four tiers. The Unacceptable tier covers prohibited practices (social scoring, real-time biometric ID in public spaces under most conditions, manipulative techniques, exploitation of vulnerabilities) and entered application on 2 February 2025. A target operating in any Unacceptable-tier use case is a walk for any EU-touching buyer. The High-Risk tier covers Annex III use cases — recruitment scoring, credit scoring, education access, law enforcement, biometric identification, critical infrastructure, employment monitoring — and carries the heaviest deal-cycle weight because the August 2026 enforcement date arrives during the typical deal pipeline. The Limited-Risk tier covers chatbots and synthetic-content generators, with Article 50 transparency obligations also entering force on 2 August 2026. The Minimal-Risk tier is everything else, with no obligations beyond voluntary codes of conduct.
Mechanism two — deferred-enforcement uncertainty. The European Commission published the Digital Omnibus on AI on 19 November 2025 proposing to defer high-risk obligations from 2 August 2026 to 2 December 2027. If the Omnibus is not formally adopted before 2 August 2026, the original AI Act provisions, including the high-risk obligations and their current timeline, will apply as written. Buy-side counsel still prices to the August 2026 baseline because the Omnibus is a proposal until formally adopted. The deal-economic consequence: a target whose product sits in High-Risk and whose conformity assessment is not yet complete carries a $200K to $2M compliance-readiness chip depending on use-case complexity.
Mechanism three — GPAI model obligations already in force. The governance rules and the obligations for general-purpose AI (GPAI) models became applicable on 2 August 2025. A target that builds or distributes a GPAI model (typically anything trained on broad data and adaptable to a wide range of tasks) has been operating under those obligations since then — documentation requirements, transparency obligations, copyright-policy disclosure, training-data summary publication. The Act will apply from 2 August 2027 to GPAI models that were placed on the market before 2 August 2025; for everything placed after that date, the obligations apply immediately. The audit question: does the target maintain a model card, a training-data summary, and a copyright-compliance policy aligned with GPAI requirements?
Mechanism four — conformity assessment evidence. For High-Risk Annex III systems, the conformity assessment file is the gating evidence pack. It includes the risk-management system documentation, the technical documentation per Annex IV, the data-governance procedures, the post-market monitoring plan, the human-oversight procedures, the cybersecurity measures, and the EU declaration of conformity. A target with a complete conformity assessment file scores 4-5 on the Governance Layer of the 5-Layer Audit; a target with no conformity assessment file and an August 2026 deal-close date scores 1-2 and carries the full compliance-readiness chip.
The EU AI Act Exposure Scoring Matrix is the diligence frame that maps the target's actual use cases against the four tiers and surfaces the conformity-assessment evidence required. Buyer counsel walks the matrix in three passes: pass one inventories every use case the target's AI deploys against (typically 3-12 use cases per target); pass two classifies each use case into one of the four tiers; pass three demands the conformity-assessment evidence for any High-Risk use case and the transparency-disclosure evidence for any Limited-Risk use case. The deliverable is a one-page exposure summary signed by target counsel, with the gap-list and remediation-cost estimate attached. The matrix output then feeds the broader regulatory request list inventoried in the due diligence data room checklist.
What does the 5-Layer AI Target Audit cover?
The 5-Layer AI Target Audit is the proprietary diligence frame that decomposes any AI-using target into five auditable layers, scores each from 1 to 5, and produces a composite AI Deal Health Score from 5 to 25 with three actionable bands. The frame answers a specific buyer question: where exactly is the AI risk in this target, and what is the deal-cycle action that follows?
| Layer | What to ask | Red flags | Score 1-5 | Typical repricing |
|---|---|---|---|---|
| Data | Training data provenance, license trail, PII exposure, scrape risk | Pirated corpora (LibGen / Anna's Archive / Pirate Library Mirror), unlicensed scraped content of copyrighted works, no deletion-on-request log, PII in training corpora | 1-5 | 5-25% on serious findings |
| Model | Proprietary vs licensed, license-cliff terms, fine-tune lineage, model-risk register | Llama 700M MAU cliff approaching, no model cards, fine-tune training data is the in-licensed model's output, no model-risk register | 1-5 | 3-15% on license-cliff |
| Infrastructure | GPU contracts, capacity guarantees, cloud concentration, BIS export-control posture | More than 70% on one hyperscaler, no committed capacity letter, no disaster-recovery test, missing BIS classification record | 1-5 | 5-20% on concentration |
| Output | FTC AI-claims exposure, hallucination liability, indemnification posture, insurance rider | Aggressive marketing claims ("first robot lawyer," "replace your accountant"), no incident log, customer indemnification carve-outs missing | 1-5 | 5-15% on claims exposure |
| Governance | EU AI Act tier classification, conformity assessment file, NIST AI RMF program, red-teaming cadence | No tier classification, no conformity assessment file for High-Risk uses, no red-teaming log, no AI risk register | 1-5 | 5-25% on missing conformity |
The composite AI Deal Health Score sums the five layer scores. The bands map to deal action: 5-10 walk or restructure to asset-only purchase (the AI-specific risk is large enough that an equity acquisition exposes the buyer to indemnification claims that exceed the deal value); 11-17 price-chip negotiation with escrow or earn-out (the AI-specific risk is real but quantifiable, and the deal closes at a discount with retention mechanics protecting the buyer); 18-25 healthy AI target (no AI-specific repricing required beyond standard rep-and-warranty insurance pricing).
The 5-Layer Audit operates as a structured workstream with its own document checklist and visitor-group access pattern in the data room. The Data Layer audit takes the longest (typically 2-4 weeks for a serious target) because training-data provenance requires per-dataset traceability. The Governance Layer audit is the most time-sensitive because the EU AI Act August 2026 enforcement date intersects directly with deal-cycle pricing. The Output Layer audit is the most heavily lawyered because FTC consent decrees create binding precedent.
The 5-Layer Audit maps onto the data room structure through five top-level folders gated through visitor groups. The Data Layer folder holds training-data manifests, license documentation, opt-out compliance logs, and deletion-on-request records. The Model Layer folder holds model cards, fine-tune lineage documentation, eval-suite results, and model-risk registers. The Infrastructure Layer folder holds GPU contracts, capacity commitment letters, cloud-spend breakdowns, disaster-recovery test logs, and export-control classification records. The Output Layer folder holds the marketing-claims register, customer complaint logs, hallucination-incident database, and customer-contract indemnification provisions. The Governance Layer folder holds the AI risk register, conformity assessment file, post-market monitoring plan, incident response procedures, and red-team logs — best surfaced from a dedicated AI room that keeps the high-sensitivity governance artifacts isolated from the rest of the deal-room scope.
The 5-Layer Audit ties into the broader M&A diligence scope through specific seams. The Data Layer touches IP diligence (copyright posture on scraped training corpora) and privacy diligence (PII in training data, GDPR Article 17 deletion exposure). The Model Layer touches IP diligence (license terms, derivative-work restrictions) and accounting diligence (model amortization treatment, R&D capitalization). The Infrastructure Layer touches commercial diligence (vendor concentration, capacity guarantees) and operational diligence (continuity risk). The Output Layer touches commercial diligence (customer-contract indemnification) and regulatory diligence (FTC, state AG enforcement). The Governance Layer touches regulatory diligence (EU AI Act, NIST AI RMF) and compliance diligence (audit program maturity). The structural diligence anchor across the workstreams is the M&A due diligence process guide.
How do you audit the Data Layer — training provenance, PII, scrape risk?
The Data Layer audit is the heaviest of the five and the one where 2024-2026 case law has materially repriced risk. The 5-Layer Audit gives Data Layer a score from 1 to 5 based on five diagnostic tests — training-data provenance, license documentation, scraped-content posture, PII inventory, and opt-out / deletion-on-request compliance — with each test scored Pass / Yellow / Red and the layer score derived from the worst-case combination.
Diagnostic test one — training-data provenance. Every dataset used to train a target's proprietary model (foundation or fine-tune) needs documented provenance: source name, acquisition date, license terms with effective date, intended-use scope, and the licensee-of-record. The buyer's data-counsel team reads the training-data manifest and traces each dataset to its origin. The acceptable evidence stack: per-dataset license agreement, dataset-card documentation, source-of-truth identifier, and the deletion log for any dataset that has been removed from training (typically post-DMCA, post-GDPR Article 17, or post-customer opt-out). The unacceptable evidence stack: a single line item reading "publicly available web data" with no further documentation, scraped content from sites with terms-of-service prohibiting scraping, or any dataset acquired from a torrent-tracker or shadow-library source.
Diagnostic test two — license documentation. Every licensed dataset needs license documentation effective on the training run date. Commercial-use clauses, derivative-works clauses, attribution requirements, and effective-date language all need explicit review. The buyer's data-counsel team checks for license-mismatch (training was completed under a license that has since been revoked or downgraded) and for attribution-gap (the target's product owes attribution to a dataset source that was never credited). The exposure is quantifiable: the Anthropic Bartz settlement of $1.5 billion approved by Judge William Alsup on 25 September 2025 priced the per-work damages at approximately $3,000 per book for an estimated 500,000 books, establishing a baseline-per-work damages number that buyer counsel now multiplies against the target's likely-pirated training-corpus volume.
Diagnostic test three — scraped-content posture. The buyer's data-counsel team asks the binary question: did the target's training corpora include any content scraped from shadow libraries (Library Genesis, Anna's Archive, Pirate Library Mirror, Z-Library)? The answer comes from the training-data manifest, from engineering-team interviews, from the data-acquisition-purchase trail, and from internal Slack archives if the target opens them. The Bartz court ruled in June 2025 that downloading from shadow libraries was not protected fair use even where the downstream training use might be — the piracy itself was the actionable claim. A target with documented shadow-library training-corpus content scores 1 (Red) on this test regardless of post-detection cure unless the cure includes substantial settlement payment, retraining from clean corpora, and customer notification.
Diagnostic test four — PII inventory. Any PII in training corpora creates GDPR Article 17 (right to erasure) exposure, CCPA exposure, and state-law biometric privacy exposure. The buyer's privacy-counsel team requires a PII inventory across all training datasets, the data-protection impact assessment (DPIA) for any dataset containing PII, and the deletion-on-request workflow showing how customer or data-subject deletion requests propagate from production data through to training corpora and any fine-tuned model derived from them. In the data room, the PII inventory itself is staged behind NDA gates at the model-card folder and surfaced through redaction for any identifier-level fields the seller cannot share without further legal review. The technical reality: deleting from training corpora does not delete from a trained model — but the buyer requires documented evidence of the model-retraining or unlearning approach taken to honor deletion requests. A target with no PII inventory and no documented deletion-on-request workflow scores 1-2.
Diagnostic test five — opt-out and deletion compliance. Beyond GDPR Article 17, the buyer's data-counsel team reviews the target's response posture to publisher opt-outs (the NYT case discovery order of January 2026, where US District Judge Sidney Stein affirmed compelling OpenAI to produce a 20-million-log sample of anonymized ChatGPT conversations, set the precedent that AI companies must preserve user logs against future copyright discovery). The target needs documented opt-out compliance for any website using the robots.txt AI-crawler directives, any DMCA notice received, and any GDPR Article 17 request received. The buyer also reviews the user-log preservation policy because litigation-preservation obligations now flow from preservation orders, not just from internal retention schedules.
The Data Layer score derives from the worst-case test result. A target with documented per-dataset provenance, clean license trails, no shadow-library content, complete PII inventory, and documented opt-out compliance scores 5 (Pass-Pass-Pass-Pass-Pass). A target with one Yellow (license-mismatch on one dataset, partial PII inventory) and four Pass scores 3-4. A target with one Red (shadow-library content, no PII inventory) scores 1-2 regardless of how clean the other four tests are. The proprietary insight: shadow-library content posture is the highest-information-content test because it produces the most quantifiable downside risk per the Bartz settlement precedent.
The Data Layer feeds the broader IP-diligence and privacy-diligence workstreams covered in the M&A due diligence process guide and the vendor due diligence checklist. The deal-cycle handoff: data-counsel completes the Data Layer audit, surfaces findings into the data-room Q&A, and the IP and privacy workstreams use the Data Layer findings to size their own indemnification and rep-and-warranty asks.
How do you audit the Model Layer — ownership, license terms?
The Model Layer audit traces every model in the target's stack to its license posture, identifies any license-cliff trigger, and scores the model-risk-management discipline. Five diagnostic tests anchor the audit: model-inventory completeness, license-term clarity, fine-tune lineage, model-card archive, and model-risk-management register.
Diagnostic test one — model-inventory completeness. The buyer's tech-counsel team requires a complete model inventory across the target's stack: every foundation model, every fine-tune, every open-source model embedded in product, every third-party model accessed via API, and every model used internally for ops, sales, or marketing. For each model: model name, license terms, version, training-data summary, intended-use scope, and the in-production indicator. A target with a complete model inventory scores 4-5 on this test; a target where the engineering team can identify only the top-three models out of a stack of ten scores 1-2.
Diagnostic test two — license-term clarity. Each licensed model needs a clean license-term review. The two most material 2025-2026 license-cliff terms: (1) the Llama 3 / Llama 3.1 700-million-monthly-active-user cap, which terminates free commercial use at 700M MAU on the version release date — if the target operates at scale and any product uses Llama as a backbone, the buyer requires a contingency plan if the MAU threshold is crossed; and (2) the competitor restriction in the Llama license that blocks entire product classes regardless of MAU. The Mistral commercial terms need parallel review. The Anthropic AUP needs review for any enterprise customer of the target using Anthropic's models in regulated use cases. A target with documented license-term compliance and a contingency plan for license-cliff scenarios scores 5; a target with an undisclosed cliff approaching scores 1-2.
Diagnostic test three — fine-tune lineage. Every fine-tuned model in the target's product stack needs lineage documentation: what base model was fine-tuned, what data was used to fine-tune, what license attaches to the fine-tune output, and what derivative-work restrictions apply. The Llama license explicitly prohibits using Llama materials or output to improve any other large language model excluding Meta Llama 3 or derivative works — a target that fine-tuned a Llama base and then used Llama output to train a downstream non-Llama-derivative model is in clear violation of the license. The audit asks: is every fine-tune in the stack training-data-traceable to a license-compliant source? A target with documented fine-tune lineage scores 5; a target with engineering team admission of cross-model training scores 1-2.
Diagnostic test four — model-card archive. Each production model needs a model card per the NIST AI RMF July 2024 Generative AI Profile (NIST.AI.600-1) and per the EU AI Act GPAI obligations effective 2 August 2025. The model card documents intended use, performance metrics, bias evaluation, safety evaluation, training-data summary, environmental footprint estimate, and limitations. The model-card archive sits in a data room with page-level analytics so the seller can see which model cards specialist counsel actually reads end-to-end versus which they skim. A target with model cards for every production model scores 5; a target with model cards only for the flagship product scores 3; a target with no model cards scores 1-2.
Diagnostic test five — model-risk-management register. Financial-services targets, healthcare targets, and any target deploying AI in regulated use cases need a model-risk-management (MRM) program aligned with the OCC 2011-12 framework or equivalent. The MRM register documents every model, its inherent risk tier, its validation schedule, its monitoring metrics, and its retirement criteria. For non-regulated targets, the equivalent is the NIST AI RMF-aligned risk register. A target with an MRM register reviewed quarterly scores 5; a target with a static one-time risk register scores 3; a target with no register scores 1-2.
The Model Layer score derives from the worst-case test result. The license-cliff test is the most material because the consequence is binary — either the target's product is in license compliance, or the target is operating in license violation with potential injunctive remedies. The proprietary insight: the Llama license-cliff at 700M MAU is the single most underappreciated license-cliff term in 2026 because the threshold is non-trivial to cross but non-trivial to monitor — many fast-scaling targets are not actively monitoring their MAU against the Llama threshold and only discover the exposure in diligence. The cliff documentation handoff feeds the buyer-side Q&A workflow described in the due diligence questionnaire guide.
The Model Layer feeds into the broader tech-DD and IP-DD workstreams covered in the startup due diligence guide (for founder-stage targets where the AI is the product) and the M&A due diligence process guide (for the hub-canonical workstream relationships). The deal-cycle handoff: tech-counsel completes the Model Layer audit, surfaces license-cliff findings into the data-room Q&A, and the IP workstream uses the Model Layer findings to size license-cliff indemnification asks.
How do you audit the Infrastructure Layer — GPU contracts, vendor concentration?
The Infrastructure Layer audit covers the compute supply chain the target depends on: GPU contracts, cloud provider concentration, capacity guarantees, disaster recovery posture, and BIS export-control compliance. Five diagnostic tests anchor the audit: GPU contract terms, capacity commitment letter, cloud concentration ratio, disaster recovery test log, and export-control classification record.
Diagnostic test one — GPU contract terms. Targets running their own model training or large-scale inference workloads need committed-capacity GPU contracts. The buyer's tech-counsel team reads each GPU contract for: committed capacity (number of GPUs and hours), allocation guarantees (priority versus best-effort), force-majeure clauses, termination triggers, pricing structure (fixed versus indexed), and renewal mechanics. A common 2025-2026 finding: targets running on hyperscaler-hosted GPU capacity have only best-effort allocation with no committed-capacity SLA, which becomes a continuity risk in capacity-constrained quarters. A target with documented committed-capacity contracts scoring well above peak demand requirement scores 5; a target running on best-effort allocation only scores 1-2.
Diagnostic test two — capacity commitment letter. Beyond the contract terms, the buyer's tech-counsel team requires a capacity commitment letter from each GPU provider summarizing the committed-capacity scope and any near-term capacity expansion plans. The commitment letter is the buyer's evidence that the target's growth model is compute-supportable through the deal-close horizon and the first 12-18 months of post-close operations. A target with capacity commitment letters covering the next 18 months scores 5; a target with no commitment letter scores 1-2.
Diagnostic test three — cloud concentration ratio. The buyer's tech-counsel team computes the cloud concentration ratio: what percentage of the target's compute spend runs on a single hyperscaler? More than 70 percent on one provider is a chip-on-the-table flag because it creates renewal-leverage risk and vendor-lock-in exposure. The Anthropic-Google and Anthropic-Amazon strategic relationships through 2024-2026 illustrate why concentration matters — strategic-customer relationships at this scale often come with commercial-side commitments that effectively lock the target into the provider's stack. A target with cloud concentration below 50 percent on any single provider scores 5; above 70 percent scores 2-3; above 90 percent scores 1.
Diagnostic test four — disaster recovery test log. Targets running production AI workloads need documented disaster-recovery (DR) testing on a defined cadence. The DR test log documents the test scope, the date, the recovery time objective (RTO) achieved, the recovery point objective (RPO) achieved, and any gaps identified. A target with quarterly DR tests showing achievable RTO under 4 hours scores 5; a target with annual DR tests scores 3; a target with no documented DR testing scores 1-2.
Diagnostic test five — BIS export-control classification record. Targets serving international customers need a BIS Export Administration Regulations (EAR) classification record for any AI-related technology or model exported. The January 2026 BIS final rule revising the license-review posture for NVIDIA H200- and AMD MI325X-equivalent chips from "presumption of denial" to "case-by-case review" effective 15 January 2026 changed the compliance calculus. The January 2026 25-percent tariff on covered products (advanced AI chips not destined for the US supply chain) added a parallel duty consideration. The November 2025 suspension of the BIS Affiliates Rule for one year removed one compliance lever but left others. The export-control file lives in a permissions-controlled data room with link expiry so outside trade counsel get time-boxed access only. A target with documented BIS classifications, export licenses where required, and a screening program for foreign-affiliate destinations scores 5; a target with no BIS classification record scores 1-2.
The Infrastructure Layer score derives from the worst-case test result, weighted toward the cloud-concentration and GPU-contract tests because those create the most immediate continuity risk. The proprietary insight: GPU-contract concentration is the single most common Infrastructure Layer finding in 2025-2026 because hyperscaler-hosted AI workloads default to best-effort allocation unless the customer specifically negotiates committed-capacity terms — and most early-to-mid-stage AI targets did not negotiate committed-capacity terms during their initial cloud agreement.
The Infrastructure Layer feeds into the broader operational-diligence and commercial-diligence workstreams covered in the vendor due diligence checklist and the due diligence cost breakdown. The deal-cycle handoff: tech-counsel completes the Infrastructure Layer audit, surfaces concentration findings into the data-room Q&A, and the operational workstream uses the Infrastructure Layer findings to size business-continuity indemnification asks.
How do you audit the Output Layer — hallucination, FTC AI-claims exposure?
The Output Layer audit prices the marketing-claim and customer-deliverable risk arising from AI output behavior. Five diagnostic tests anchor the audit: marketing-claim posture, customer-complaint log, hallucination-incident database, customer-contract indemnification, and insurance carrier AI-rider terms.
Diagnostic test one — marketing-claim posture. The buyer's regulatory-counsel team reviews every public marketing claim about AI capability, accuracy, or substitutability. The FTC Operation AI Comply enforcement sweep launched 25 September 2024 cracked down on deceptive AI claims and schemes. The DoNotPay final order announced 13 February 2025 required $193,000 in monetary relief, prohibits DoNotPay from advertising that its service performs like a real lawyer unless it has sufficient evidence to back it up, and requires notice to past subscribers between 2021 and 2023 — DoNotPay's claim of being "the world's first robot lawyer" was the trigger. The FTC Rite Aid case (December 2023) banned facial-recognition use for security or surveillance for five years after finding the technology produced more false-positive results for Black and Latino customers. A target with conservative marketing claims, signed-off by counsel, with substantiation files for each claim scores 5; a target with aggressive marketing claims and no substantiation files scores 1-2.
Diagnostic test two — customer-complaint log. The buyer's regulatory-counsel team reviews the target's complaint log for any complaints alleging AI inaccuracy, AI bias, AI harm, or AI substitution failure. The log inventory: source of complaint (customer, regulator, media), date, complaint substance, target's response, and resolution. A target with a documented complaint log showing low volume and prompt resolution scores 5; a target with a complaint log showing pattern-of-issue or recurring inaccuracy complaints scores 2-3; a target with no complaint log scores 1.
Diagnostic test three — hallucination-incident database. Production GenAI deployments need a hallucination-incident database documenting each material false-output incident: customer impact, root-cause analysis, mitigation deployed, and recurrence indicator. The database is the operational evidence pack that the target takes hallucination risk seriously. When the seller surfaces the hallucination log into the data room, dynamic watermarks burned into every page deter casual leakage to journalists or short-sellers. A target with a documented hallucination-incident database and quarterly review scores 5; a target with no formal hallucination tracking scores 1-2.
Diagnostic test four — customer-contract indemnification. The buyer's commercial-counsel team reads every material customer contract for AI-specific indemnification provisions. Does the target indemnify customers for AI-output errors? Does the target carve out AI-output from liability caps? Does the target preserve the right to inject disclaimers into AI-output? The 2025-2026 baseline: enterprise customers increasingly require AI-output indemnification, but mature targets carve out indemnification specifically for hallucinations attributable to documented model limitations. A target with consistent AI-output indemnification posture across customer contracts scores 5; a target with inconsistent posture or open-ended indemnification exposure scores 2-3.
Diagnostic test five — insurance carrier AI rider. The target's commercial general liability, errors-and-omissions, and cyber insurance policies need AI riders. The 2024-2026 development: insurers added AI-specific exclusions and AI-specific riders, and the rider terms vary widely. A target with documented AI riders on all material policies and with the rider scope reviewed by counsel scores 5; a target with no AI rider scores 1-2.
The Output Layer score derives from the worst-case test result. The marketing-claim posture test is the most material because it determines the FTC and state-AG enforcement exposure surface. The proprietary insight: the FTC Operation AI Comply enforcement pattern through 2024-2026 (DoNotPay, Rite Aid, and the September 2024 Operation AI Comply sweep) plus the FTC's December 2025 Rytr final order set aside under the Trump Administration's AI Action Plan show that the enforcement target shifted from broad AI claims toward specific deceptive-claim patterns — but the underlying risk surface remains the marketing-claim register and the substantiation files.
The Output Layer feeds into the broader regulatory-diligence workstream covered in the hub-canonical M&A diligence playbook and the commercial workstream. The deal-cycle handoff: regulatory-counsel completes the Output Layer audit, surfaces marketing-claim findings into the data-room Q&A, and the commercial workstream uses the Output Layer findings to size customer-indemnification asks.
How do you audit the Governance Layer — EU AI Act tier, NIST AI RMF, red-teaming?
The Governance Layer audit confirms the target's compliance posture under the EU AI Act and the NIST AI RMF, and reviews the red-teaming cadence and AI risk register. Five diagnostic tests anchor the audit: EU AI Act tier classification, conformity assessment file, NIST AI RMF program, red-team log, and AI risk register.
Diagnostic test one — EU AI Act tier classification. The buyer's regulatory-counsel team requires the target's EU AI Act tier classification across every use case (typically 3-12 per target). The classification document maps each use case to one of four tiers: Unacceptable (prohibited, applied 2 February 2025), High-Risk (Annex III, applies 2 August 2026 unless deferred by the Digital Omnibus to 2 December 2027), Limited-Risk (Article 50 transparency, applies 2 August 2026), or Minimal-Risk (no obligations). A target with a complete tier classification reviewed by EU counsel scores 5; a target with no tier classification scores 1-2.
Diagnostic test two — conformity assessment file. For any use case classified as High-Risk, the conformity assessment file is the gating evidence pack required by 2 August 2026 (or 2 December 2027 if the Digital Omnibus is formally adopted). The file includes the risk-management system documentation, technical documentation per Annex IV, data-governance procedures, post-market monitoring plan, human-oversight procedures, cybersecurity measures, and EU declaration of conformity. A target with a complete conformity assessment file for every High-Risk use case scores 5; a target with a partial file scores 2-3; a target with no file and August 2026 deal-close scores 1.
Diagnostic test three — NIST AI RMF program. The buyer's regulatory-counsel team reviews the target's NIST AI RMF 1.0 alignment plus the July 2024 Generative AI Profile (NIST.AI.600-1). The four functions of the AI RMF — Govern, Map, Measure, Manage — each need documented procedures, owners, and review cadence. The GenAI Profile adds focus on confabulation, data privacy, harmful bias, and misuse. A target with documented AI RMF program alignment scores 5; a target with selective alignment scores 3; a target with no AI RMF program scores 1-2.
Diagnostic test four — red-team log. Production GenAI deployments need a red-team log documenting cadence (quarterly minimum for production GenAI, monthly for safety-critical deployments), test scope, findings, and remediation. The red-team test scope covers prompt injection, jailbreak resistance, data exfiltration, bias evaluation, harmful-content generation, and use-case-specific safety tests. A target with quarterly red-teaming, documented findings, and remediation tracking scores 5; a target with annual red-teaming scores 3; a target with no red-teaming scores 1-2.
Diagnostic test five — AI risk register. The AI risk register is the operational artifact that ties all four prior tests together. It documents every AI risk the target has identified, the risk owner, the mitigation in place, the residual risk score, and the review cadence. A target with an AI risk register reviewed quarterly by the executive AI committee scores 5; a target with a static risk register scores 3; a target with no AI risk register scores 1-2.
The Governance Layer score derives from the worst-case test result, weighted toward the EU AI Act tier and conformity-assessment tests because those drive direct compliance exposure. The proprietary insight: the absence of an AI risk register and a documented red-teaming cadence is the single most common Tier 1 Governance Layer finding in 2025-2026 — many AI-using targets have NIST AI RMF familiarity at the engineering level but have not formalized the governance artifacts at the executive level. Buyer counsel requires the executive-level artifacts.
The Governance Layer feeds into the broader regulatory-diligence workstream covered in the end-to-end M&A diligence sequence and the compliance workstream. The deal-cycle handoff: regulatory-counsel completes the Governance Layer audit, surfaces AI Act and AI RMF findings into the data-room Q&A, and the compliance workstream uses the Governance Layer findings to size remediation-readiness chips.
Which 2025-2026 deals were AI-repriced, AI-stopped, or AI-talent-absorbed?
Twelve deals in 2024-2026 anchor the modern AI DD reference set. Each illustrates a specific AI-DD-relevant element that buyer counsel cites when negotiating reps, warranties, indemnification, and price.
One — Microsoft-Inflection AI ($650 million license + acqui-hire, March 2024). Microsoft paid $650 million to license Inflection's technology and hire most of its 70-person workforce including co-founder Mustafa Suleyman. The structure: $620 million for a non-exclusive license to AI models and $30 million to waive legal rights related to mass hiring. The FTC opened an informal inquiry in June 2024 and the UK CMA opened a probe shortly after. The diligence frame Microsoft-Inflection established: the reverse-acquihire structure as an alternative to a traditional acquisition that would have triggered HSR review. The 2026 deal-cycle implication: any buyer evaluating a reverse-acquihire path against a traditional acquisition must price the post-close FTC inquiry probability.
Two — Google-Character.AI ($2.7 billion reverse-acquihire, August 2024). Google paid $2.7 billion to re-hire co-founders Noam Shazeer and Daniel De Freitas (both former Google employees) and license Character.AI technology. The structure attracted DOJ formal investigation by mid-2025 and an FTC staff report concluding such pseudo-acquisitions could constitute unfair competition by depriving rivals of essential engineering talent. In January 2026, Google and Character.AI moved to settle lawsuits over teen suicides linked to AI chatbots. The diligence frame Google-Character.AI established: AI safety and youth-protection liability flowing from chatbot product behavior, separate from the antitrust review of the deal structure.
Three — Amazon-Adept AI (June 2024). Amazon hired Adept co-founder David Luan and approximately 66 percent of Adept's 100-employee team, and licensed Adept's technology, multimodal models, and some datasets for a $25 million licensing fee. Adept investors were paid back through the licensing proceeds. The FTC opened an informal inquiry. The diligence frame Amazon-Adept established: the licensing-fee-only-no-equity transfer structure that is HSR-exempt because no voting securities or assets transfer.
Four — Stability AI Sean Parker-led rescue (June 2024). Sean Parker and an investor group including Greycroft, Coatue Management, Sound Ventures, and Lightspeed Venture Partners closed a rescue round (approximately $80M new equity plus approximately $400M debt forgiveness organized by Parker with creditors). Prem Akkaraju became CEO; Sean Parker became Executive Chairman. By December 2024, the company had erased all debt and delivered triple-digit revenue growth. WPP added a strategic investment in 2025. The diligence frame Stability AI established: the AI restructuring playbook for distressed-AI targets — debt forgiveness plus new-equity plus executive-team turnover, executed without receivership.
Five — Anthropic Bartz v. Anthropic settlement ($1.5 billion, September 2025). Judge William Alsup of the Northern District of California gave preliminary approval on 25 September 2025 to a settlement requiring Anthropic to pay approximately $1.5 billion (approximately $3,000 per book for roughly 500,000 works) to resolve claims that Anthropic downloaded pirated books from shadow libraries (Library Genesis, Pirate Library Mirror) to train Claude. Judge Alsup's June 2025 summary-judgment ruling: using legally-acquired books to train AI was fair use; pirating books to train AI was not. The diligence frame Bartz established: the per-work damages baseline for any AI target with shadow-library training-corpus exposure, plus the binary-cure framework (retraining from clean corpora, settlement, customer notification).
Six — Universal Music / Concord et al. v. Anthropic (filed January 2026 by major music publishers, $3 billion+ damages alleged). Concord Music Group, UMG, and ABKCO sued Anthropic in late January 2026 alleging Anthropic illegally downloaded more than 20,000 copyrighted songs including sheet music, lyrics, and compositions — described as potentially the largest non-class-action copyright case in US history. Anthropic had earlier entered into a January 2025 partial-settlement on a separate music-publisher case to avoid an injunction. The diligence frame: music-publisher litigation extends the Bartz-precedent damages model to a new content vertical and signals continued copyright-exposure layering.
Seven — New York Times v. OpenAI / Microsoft (20-million-log discovery order, January 2026). US District Judge Sidney Stein affirmed a magistrate judge's order compelling OpenAI to produce the entire 20 million-log sample of anonymized ChatGPT conversations, not just plaintiff-selected logs. The earlier May 2025 demand had been for 1.4 billion logs; the discovery order narrowed to 20 million. Summary judgment is scheduled for April 2026. The diligence frame NYT v. OpenAI established: user-log preservation as a litigation hold obligation, with consequence for data-retention policy and infrastructure cost. Any AI target with user-log volume in the hundreds of millions or above needs documented preservation-policy design.
Eight — OpenAI Sora 2 launch (30 September 2025) and opt-out reversal. OpenAI launched Sora 2 with an opt-in for likeness (cameo feature) but opt-out for copyright — users could generate videos with copyrighted characters unless rightsholders explicitly opted out. Within days, the Motion Picture Association demanded immediate action. Three days post-launch, OpenAI reversed to an opt-in model for copyrighted characters. By 2026 the Disney $1B partnership enabled licensed Disney characters in Sora 2 output. The diligence frame Sora 2 established: opt-in versus opt-out as the binary content-rights design choice for any generative product, with rapid-reversal capability becoming part of the product-architecture diligence question.
Nine — xAI $20 billion Series E at $230 billion valuation (January 2026), absorbed into SpaceX (February 2026). xAI closed a $20 billion Series E in January 2026 at $230 billion valuation (upsized from $15 billion target) including Valor Equity Partners, StepStone Group, Fidelity, Qatar Investment Authority, MGX, Baron Capital, Nvidia, Cisco Investments, and Tesla (the Tesla commitment was approximately $2 billion subject to regulatory approvals). In February 2026, SpaceX acquired xAI in an all-stock deal valuing the combined entity at $1.25 trillion (SpaceX at $1 trillion, xAI at $250 billion) — the largest private corporate merger in history. The diligence frame xAI-SpaceX established: the AI-target absorption-into-strategic-acquirer pattern at scale, with valuation discipline maintained through the all-stock structure rather than cash-out.
Ten — FTC Operation AI Comply, DoNotPay final order ($193,000, February 2025) and Rytr final order set aside (December 2025). The DoNotPay February 2025 final order required $193,000 in monetary relief, prohibits the company from advertising that its service performs like a real lawyer unless it has sufficient evidence to back it up, and requires notice to past subscribers between 2021 and 2023. In December 2025, the FTC reopened and set aside the Rytr final order in response to the Trump Administration's AI Action Plan — signaling a shift in FTC enforcement posture but not a withdrawal of the underlying Operation AI Comply enforcement framework. The diligence frame: FTC AI-claims enforcement remains active, but the specific enforcement-priority mix is shifting under the new Administration.
Eleven — FTC Rite Aid Corporation facial-recognition five-year ban (December 2023). The FTC banned Rite Aid from using facial-recognition technology for security or surveillance for five years after finding the technology produced more false-positive results for Black and Latino customers and that Rite Aid failed to implement reasonable procedures. The five-year ban runs through approximately December 2028, well into typical M&A deal cycles. The diligence frame Rite Aid established: facial-recognition and biometric-ID use as a board-level governance risk with explicit FTC consent-decree precedent.
Twelve — BIS H200 / MI325X chip licensing rule (January 2026) and Hart-Scott-Rodino threshold increase ($133.9 million effective 17 February 2026). The BIS final rule of 13 January 2026, effective 15 January 2026, revised the license-review posture for NVIDIA H200- and AMD MI325X-equivalent chips from presumption-of-denial to case-by-case review. On 14 January 2026, the Trump Administration imposed a 25-percent value-based tariff on covered products effective 15 January 2026. The HSR Size-of-Transaction threshold was revised from $126.4 million in 2025 to $133.9 million effective 17 February 2026 (a 5.9 percent increase). The diligence frame: BIS export-control posture is now a deal-by-deal modeling exercise rather than a clean-allow or clean-deny analysis, and the HSR threshold delineates which AI deals require pre-merger notification.
The twelve-deal reference set anchors the 5-Layer Audit's specific score-decisions. The Bartz precedent anchors the Data Layer scrape-risk test. The Llama license-cliff anchors the Model Layer license-term test. The xAI-SpaceX absorption anchors the Infrastructure Layer cloud-and-compute concentration test (xAI on its Memphis Colossus build versus SpaceX's existing data-center stack). The Rite Aid and DoNotPay precedents anchor the Output Layer marketing-claim posture test. The EU AI Act August 2026 enforcement and NIST AI RMF 1.0 plus the July 2024 GenAI Profile anchor the Governance Layer tier-classification and AI RMF tests. The HSR $133.9 million threshold establishes the pre-merger notification gate for any AI deal at or above the threshold.
Which AI tools genuinely speed DD vs. which are theater?
The AI-for-DD half of the AI Due Diligence frame is materially smaller than the DD-of-AI half in deal economics but materially larger in day-to-day workflow time savings. Real-DD use cases and theater use cases divide on a single test: can the AI tool cite its source paragraph for every finding, and does buyer's counsel sign off on the methodology?
Real-DD use case one — clause extraction across customer contracts. Modern LLMs can process hundreds of pages of unstructured deal-room content and surface clause types (caps, indemnities, change-of-control, MFN, exclusivity, auto-renewal, termination-for-convenience, governing law). The honest output: a clause-by-clause table with source-citation back to the specific contract paragraph. Inside Peony, AI extraction speeds the licensing-clause review the same way, with citations back to the originating contract page. A diligence team running clause extraction across 200 customer contracts can complete the workstream in 4-6 hours rather than 4-6 days. The methodology check: every finding cites the source paragraph, the LLM does not invent clauses that are not in the source, and the counsel reviewer can verify each finding against the source in 30 seconds. Real lift, real audit trail.
Real-DD use case two — redline summarization on amendment stacks. Long-running customer contracts often accumulate 5-20 amendments. Modern LLMs can summarize the net-effect changes across the amendment stack — what terms moved, what terms were added, what terms were deleted — with source-citation back to each amendment. The methodology check: the summary references the specific amendment for each change, and the counsel reviewer can verify by reading the cited amendment.
Real-DD use case three — Q&A categorization and routing. Inbound buyer Q&A in a data room can be categorized and routed to the right responder using LLM tagging. Peony's smart Q&A handles this routing with category suggestions and assignee defaults. Real lift: 30-50 percent reduction in routing time. The methodology check: the routing decision is logged with the LLM's reasoning, and the human reviewer can override any routing decision.
Real-DD use case four — financial-statement reconciliation. LLMs combined with structured-data tools can reconcile financial statements against bank records, identify timing differences, and surface unreconciled items. The methodology check: every reconciliation finding cites the specific statement line and bank-record entry.
Real-DD use case five — entity matching across customer contracts. Customer-name normalization across hundreds of contracts (handling typos, legal-name versus DBA, parent-versus-subsidiary references) is a structured task that LLMs handle well with appropriate guardrails. The methodology check: every normalization decision is logged and reversible.
Theater use case one — black-box risk scoring. Vendors that produce an "AI risk score" on a 1-100 scale from an LLM with no audit trail and no source citation are theater. The buyer's counsel cannot sign off on the methodology, and the score has no defensible deal-cycle use. The test: can the tool show what specific document features drove the score, and can the counsel reviewer verify the features against the source documents?
Theater use case two — "diligence in 24 hours" promises. Vendor pitches that promise complete diligence in 24 hours without a human reviewer in the loop are theater. The 24-hour timeline is achievable only by skipping the verification step that converts LLM output into defensible findings.
Theater use case three — AI summarization of executive Q&A with no source citation. Summarizing executive Q&A in a data room is real lift only if the summary cites the source answer. Summaries without source-citation are an audit-trail gap that counsel cannot sign off on.
The honest AI-for-DD posture: use LLMs aggressively for the structured-extraction tasks where source-citation is enforced, and avoid the black-box risk-scoring products. The deal-cycle economics: AI-for-DD shortens diligence timelines by 2-3 weeks on a typical mid-market deal, freeing senior counsel and partners for the higher-judgment Layer-3-and-4 work in the 5-Layer Audit. The timeline compression then changes the cost-stack covered in the due diligence cost breakdown — senior-counsel hours redirect to AI-specific judgment work.
How does AI DD feed the data room scope and staged disclosure?
The AI DD workstreams (DD-of-AI and AI-for-DD) feed the data room scope and the staged disclosure model through three specific mechanisms — folder structure, visitor-group access patterns, and engagement-signal monitoring. The structural pattern: every layer of the 5-Layer AI Target Audit gets its own top-level folder, every reviewer tier gets its own visitor group, and every reviewer engagement signal gets fed back to the seller's IR team for negotiation calibration.
Folder structure. The data room top-level folders for AI-using targets typically follow the 5-Layer Audit structure: 01_Data_Layer (training-data manifests, license documentation, opt-out compliance logs, deletion-on-request records), 02_Model_Layer (model cards, fine-tune lineage, eval-suite results, model-risk register), 03_Infrastructure_Layer (GPU contracts, capacity commitment letters, cloud-spend breakdown, DR test logs, export-control records), 04_Output_Layer (marketing-claims register, complaint logs, hallucination-incident database, customer-contract indemnification index, insurance riders), 05_Governance_Layer (AI risk register, EU AI Act tier classification, conformity assessment file, NIST AI RMF program, red-team log). The 5-folder structure mirrors the audit structure so reviewer-by-reviewer drill-down maps directly to layer-by-layer audit work, and manage links lets the seller revoke any over-shared layer-folder link the moment scope drifts.
Visitor-group access patterns. Each reviewer tier gets a visitor group with permission gates that surface only the relevant layer-folders. The data-counsel tier sees folders 01 and 04. The tech-counsel tier sees folders 02 and 03. The regulatory-counsel tier sees folders 04 and 05. The EU AI Act specialist counsel sees folder 05 plus the relevant 04 sub-folders. The full-deal partner sees all five folders. The visitor-group model prevents the operating tier from accidentally accessing model-card archives or AI risk registers that are properly gated to outside specialist counsel.
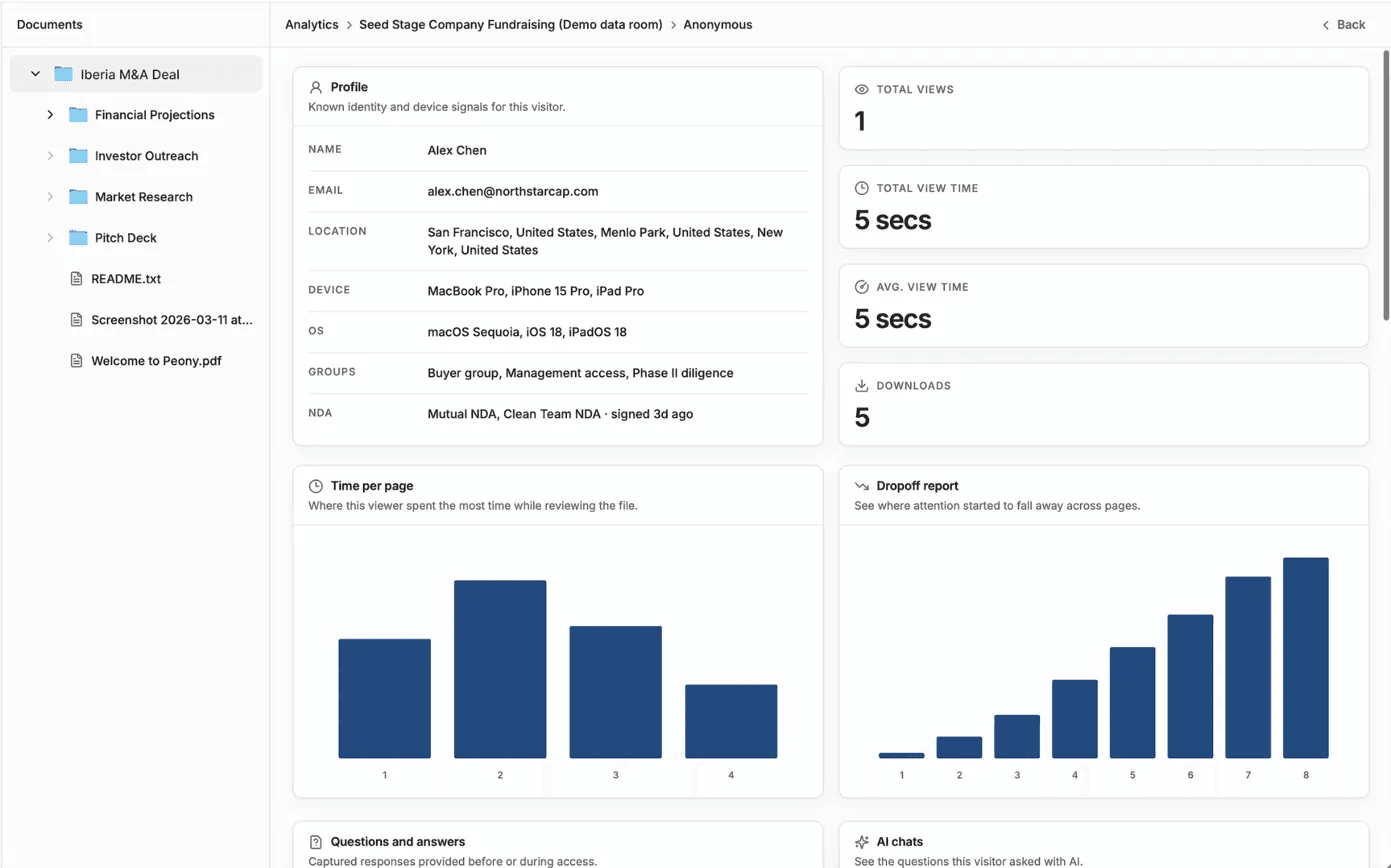
Engagement-signal monitoring. Peony's page-level analytics tell the seller's IR team which pages each reviewer tier spent time on. The data-counsel team spending 6 hours on the training-data manifest signals data-license findings are landing; the tech-counsel team spending 4 hours on Llama license-cliff documents signals license-cliff findings are landing; the regulatory-counsel team spending 3 hours on the EU AI Act conformity-assessment file signals AI Act tier classification findings are landing. The engagement-signal tells the seller's IR team where the price-chip ask will come from before the buyer's first markup of the share-purchase agreement.
The Peony brand spine. The AI-DD workstream maps onto Peony product surfaces. NDA gates sign each outside specialist counsel onto the seller's NDA template before any AI-specific folder is visible — particularly material for the training-data manifest and the AI risk register, which are both highly sensitive seller-side artifacts. Visitor groups gate each layer-folder to the relevant reviewer tier without manual permission resets. Dynamic watermarks embed firm-name plus reviewer-name plus timestamp on every model-card and conformity-assessment-file page so any leak is traceable. Screenshot protection blocks naive capture on the training-data manifest and red-team logs at the renderer level. Leak protection deters print-screen and download exfiltration on the most sensitive AI artifacts (training-data manifest, fine-tune lineage, red-team logs). Auto-indexing recognizes typical AI-target document inventory (model cards, eval suites, red-team reports, AI risk registers) across the multi-GB archive without manual folder configuration. Peony Data Room at $52/admin/month ships unlimited storage for the typical 8-15 GB AI-target archive across model-card, training-data manifest, GPU-contract, and conformity-assessment files.
The staged disclosure pattern proceeds in three waves. Wave one — the teaser-stage disclosure surfaces a one-page AI exposure summary (5-Layer Audit scores plus EU AI Act tier classification summary) before any deep folder is visible. Wave two — the LOI-stage disclosure opens the AI risk register, the model inventory, and the EU AI Act tier classification in full. Wave three — the confirmatory-DD-stage disclosure opens every layer-folder in full, including the training-data manifest, conformity-assessment file, and red-team log. The three-wave structure protects the seller's most sensitive AI artifacts (training-data manifest, red-team log) until the buyer has demonstrated sufficient seriousness through LOI and exclusivity execution. The pricing math for the seller stays simple at the Data Room plan on the pricing page: one $52/admin/month seat per deal lead, with reviewer seats free.
The broader M&A DD workstream relationships are covered in the M&A due diligence process guide. The data-room-side platform comparison and the redaction-and-permissions diligence patterns are covered in the VDR permissions guide for due diligence. The cost-side benchmarks are covered in the due diligence cost breakdown. For founder-stage targets where AI is the product, the startup due diligence guide adds the early-stage diligence frame. For the vendor-side audit pattern, the vendor due diligence checklist covers the SaaS-and-vendor angle. The fuller checklist of documents the buyer requests across all DD workstreams sits in the due diligence data room checklist.
Related resources
- IT due diligence (2026) — 6-Axis Tech-Stack Fragility Audit (parallel to AI DD's 5-Layer)
- Environmental due diligence (2026) — PFAS + CSDDD + BFPP Defense Stack
- M&A due diligence process guide — hub for the broader DD cluster
- Due diligence data room checklist — 174-document file-side companion
- Due diligence questionnaire (DDQ) — 5-persona template library
- IP due diligence — 5-Asset Encumbrance Matrix
- Operational due diligence — 8-System audit + 3-Axis severity
- Private equity due diligence — 6-strategy hold playbook
- Vendor due diligence checklist — procurement third-party risk
- Due diligence cost breakdown — what diligence really costs
- Startup due diligence guide — investor-to-startup framing
- How to securely share a Claude artifact — sharing an AI-generated diligence artifact without losing the audit trail
- Share AI-generated documents securely — the workflow for distributing AI-built CIMs, memos, and live models under watermark, NDA, and audit
- Peony pricing — Data Room at $52/admin/month
Frequently asked questions
What is AI due diligence, and how is it different from regular tech due diligence?
If you're a corp-dev associate evaluating an AI-using SaaS target with three production models, AI due diligence is the structured investigation of AI components in a target company — training data, model ownership, infrastructure dependencies, output liability, and governance — to size deal-specific risk and price-chip exposure. The 5-Layer AI Target Audit (Data / Model / Infrastructure / Output / Governance) covers what a generic tech audit misses: scraped training data with no license trail, third-party model terms that flip on a user-count threshold, GPU contracts that drop on capacity, FTC-actionable marketing claims, and EU AI Act tier obligations entering force on 2 August 2026.
How does the EU AI Act change M&A pricing for AI-using targets in 2026?
If you're EU AI Act compliance counsel scoping a target's tier exposure for a buyer, the high-risk obligations in Annex III enter application on 2 August 2026, and obligations for general-purpose AI (GPAI) models have already been in force since 2 August 2025. A target whose product sits in the High-Risk tier (recruitment scoring, credit scoring, biometric ID, critical infrastructure) carries conformity assessment, post-market monitoring, and registration duties that meaningfully shift deal economics. The Digital Omnibus proposed on 19 November 2025 would defer high-risk obligations to 2 December 2027, but until formally adopted, buyer counsel still prices to the August 2026 baseline.
What does the 5-Layer AI Target Audit actually cover, and how do I score it?
The 5-Layer AI Target Audit scores Data, Model, Infrastructure, Output, and Governance from 1 (broken) to 5 (clean) per layer, producing a composite AI Deal Health Score from 5 to 25. Bands map to deal action: 5-10 walk away or restructure to asset-only purchase, 11-17 enter price-chip negotiation with escrow or earn-out, 18-25 healthy AI target with no AI-specific repricing required. Each layer has its own diagnostic checklist, document list, and threshold benchmarks anchored against real 2025-2026 deal precedents.
How do you audit the Data Layer — training provenance, PII exposure, and scrape risk?
The Data Layer audit traces every training dataset to a documented source with a license trail, screens for scraped content of copyrighted works (the Bartz v. Anthropic $1.5 billion settlement made this exposure quantifiable), and inventories any personally identifiable information (PII) in training corpora. The buyer requires per-dataset provenance documentation, license terms with effective dates, opt-out compliance records (DMCA, GDPR Article 17), and the deletion-on-request log. The pirated-corpora question is now a binary: did training corpora include shadow library content (LibGen, Anna's Archive, Pirate Library Mirror), and if yes, is there documented post-detection cure?
How do you audit the Model Layer — proprietary versus licensed model risk?
The Model Layer audit categorizes every model in the stack as proprietary (built and trained in-house), licensed (third-party with license terms), or hybrid (fine-tuned on a base model). The Llama 3 license terminates free commercial use at 700 million monthly active users on the version release date — for a target near scale, the license-cliff is a real diligence finding. The Mistral commercial-license and Anthropic AUP-enforcement terms need parallel review. Buyers also want the model-card archive, fine-tune training-data provenance, eval-suite results, and the model-risk-management register required by the OCC 2011-12 framework or NIST AI RMF.
How do you audit the Infrastructure Layer — GPU contracts, cloud lock-in, and vendor concentration?
The Infrastructure Layer audit covers GPU contract terms (committed capacity, allocation guarantees, force-majeure clauses), cloud provider concentration (more than 70 percent on one hyperscaler is a chip-on-the-table flag), and BIS export-control posture given the January 2026 codification of NVIDIA H200- and AMD MI325X-equivalent licensing. Buyers request the GPU reservation contract, the capacity commitment letter, the cloud spend breakdown, the disaster-recovery test log, and the export-control classification record. For a target serving international customers, the BIS Affiliates Rule (suspended November 2025) and the January 2026 tariff regime need explicit modeling.
How do you audit the Output Layer — hallucination liability and FTC AI-claims exposure?
The Output Layer audit prices the marketing-claim risk under the FTC Operation AI Comply framework launched September 2024 — including the DoNotPay $193,000 final order (February 2025) and the Rite Aid facial-recognition five-year ban. Buyers review the marketing-claims register, every public statement about AI accuracy or capability, customer complaint logs, and the hallucination-incident database. The exposure scales with claim aggressiveness: 'first robot lawyer' or 'replace your accountant' attracts staff attention; 'AI-assisted drafting' does not. The buyer requires the indemnification provision in customer contracts and the insurance carrier's AI rider terms.
How do you audit the Governance Layer — EU AI Act tier, NIST AI RMF, and red-teaming cadence?
The Governance Layer audit confirms the EU AI Act tier classification (Unacceptable / High-Risk / Limited / Minimal), maps the target's risk-management program against NIST AI RMF 1.0 plus the July 2024 Generative AI Profile (NIST.AI.600-1), and reviews the red-teaming cadence. Buyers request the AI risk register, the conformity assessment file (if High-Risk), the post-market monitoring plan, the incident response procedure, and the red-team log with cadence (quarterly minimum for production GenAI). A target with no AI risk register and no red-teaming cadence is the single most common Tier 1 finding and triggers automatic Governance Layer score of 1-2.
Which 2025-2026 deals were AI-repriced, AI-stopped, or AI-talent-absorbed?
The reference set: SpaceX absorbed xAI in February 2026 in an all-stock deal valuing the combined entity at $1.25 trillion (xAI at $250 billion) — the largest private corporate merger in history. The Microsoft-Inflection ($650 million license + acqui-hire, March 2024), Google-Character.AI ($2.7 billion, August 2024), and Amazon-Adept ($25 million license + ~66 percent staff hire, June 2024) trio established the reverse-acquihire pattern and triggered FTC and CMA inquiries through 2025. The Stability AI Sean Parker-led rescue (June 2024, ~$80M new equity plus ~$400M debt forgiveness) became the playbook for distressed-AI restructuring rather than receivership.
Which AI tools genuinely speed due diligence work, versus which are theater?
If you're a PE deal partner running platform diligence on an AI-assisted services target, the real-DD use cases are clause-extraction across hundreds of contracts (caps, indemnities, change-of-control, MFN), Q&A categorization for question routing, redline summarization on amendments, financial-statement reconciliation against bank records, and trade-area entity matching. Theater: AI 'risk scoring' on a 1-100 scale derived from a black-box LLM with no audit trail, vendor pitches that promise 'AI diligence in 24 hours' without a human reviewer in the loop, and AI summarization of executive Q&A with no source-citation back to the underlying answer. The honest test: can the tool cite its source paragraph for every finding, and does the buyer's counsel sign off on the methodology?